How I created the architecture
Over the last few days I’ve been brushing up on system-design interview material, and I used that as an excuse to be deliberate about how I framed the architecture. Here’s the flow I ended up with.
With Gemini Learning, I split the work into seven buckets: functional requirements, non-functional requirements, core entities, API design, flow, high-level design, and deep dive. Having those headings forced vague thoughts into something I could actually iterate on.
LLMs are easy to nudge into agreeing with you—ChatGPT especially—once you start pitching ideas. So for each category I’d paste the conversation I’d already had and run a tighter prompt: Ask me questions and clarifications on my design until you’re 95% sure the design is complete and accounts for the usual system-design angles.
That turned into several passes and 40+ questions back and forth. It sharpened the picture in my head and surfaced blind spots. A few examples from the transcript:
Retention / cleanup
- How long do we keep the original upload, intermediate chunks, and generated stems?
- Do we delete failed-job artifacts automatically?
Functional requirements
- Can users process video directly, or do we always extract audio first?
- Can users upload multiple files in one batch?
- Can users cancel a running job?
Understanding check (answer in your own words, briefly)
- Why is direct upload to object storage better than sending the whole file through the API server?
- Why do we need a queue between the API and workers?
- Why is one
SeparationJobper retry cleaner than overwriting old outputs?
I like that last batch in particular—I’m not just rubber-stamping answers; I have to explain the tradeoffs and actually internalize them.
After that I exported the thread and asked for a full write-up using the same section structure: functional and non-functional requirements, core entities, API design, flow, high-level design, and deep dive. What came back felt complete enough to stand on: clear, consistent, and solid as a baseline.
Text isn’t the whole story, though—you still have to see the system. A former coworker pointed me at Mermaid ages ago; I’ve leaned on it since for my own notes and for getting agents aligned on the same picture. The diagrams below are what fell out of that process.
Turning this into something you’d happily implement in a repo is another layer of structure altogether—that’s what I want to tackle in the next post.
I’ll let Chatty explain the diagrams below. (All based of our discussion)
How we kept the design from turning into soup
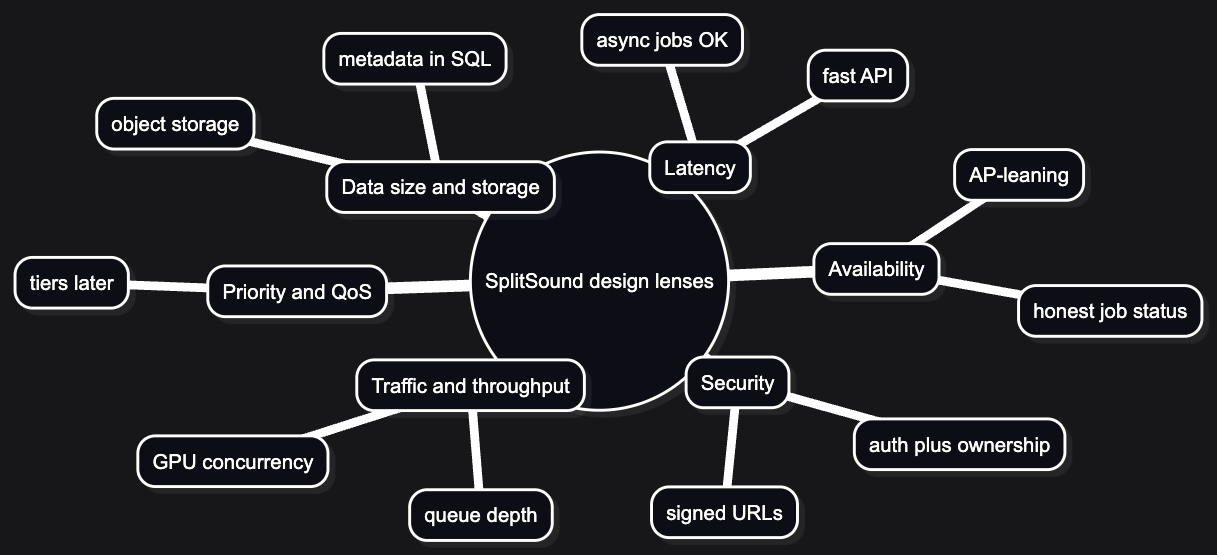
Early on, it helps to have a checklist of dimensions so every “what if?” has a shelf to sit on. We leaned on the usual system-design lenses:
Traffic and throughput matter, but for an AI-heavy workflow the interesting number is often queue depth and GPU concurrency, not raw REST RPS. Data size and storage forced the big early call: blobs live in object storage; the database holds metadata and pointers, not files. Priority and quality of service are on the roadmap (tiers, fair queuing) but we did not over-build them on day one. Latency splits cleanly: the API should feel snappy; separation can take minutes as long as status is honest. Availability we’re framing in an AP-leaning way—partition tolerance is assumed, and eventual consistency on job status is acceptable for this product class (we are not building a ledger that must be CP at all costs). Security shows up as auth, ownership checks on every job and asset, and signed URLs for upload and download—not as a late bolt-on.
A practical habit that worked for us: nail traffic and data size first; priority and failure behavior get easier once scale assumptions stop moving.
Visual: lenses we actually use
What we think we’re building (product slice)
Problem statement. Shockwave / SplitSound is a web-first, paid product: the user uploads audio or video, describes one target sound (MVP), and gets previewable, downloadable separated outputs. Long term, we want the system to propose multiple sounds and candidates with minimal typing—but MVP is deliberately narrow: one described target per job, honest async UX, credits instead of a subscription layer.
MVP slice: sign in → upload → describe the sound → wait → preview → download. Around that we still care about batch-friendly flows (several files as separate jobs, not a mystery orchestration layer), cancellation, retries as new job rows (version history, not silent overwrites), deletion of originals and outputs, credit-based billing, and internal admin visibility.
Architecture shape (physical): a modular monolith for the control plane (FastAPI today) plus a separate GPU worker service—not fifteen microservices on day one. Full microservices would buy us more deployments, IAM edges, and debug surface than we need while search traffic is still finding us. We still draw logical boundaries (frontend, API, worker, Postgres, S3, SQS, Stripe, admin UI) so the split stays obvious when we scale.
In one breath: import media (on the order of ~100 MB max, often smaller, with room to grow into chunked uploads for serious models), choose what sounds to keep or remove, download stems, and retry separation in a way that favors new job versions instead of silently overwriting someone’s last run.
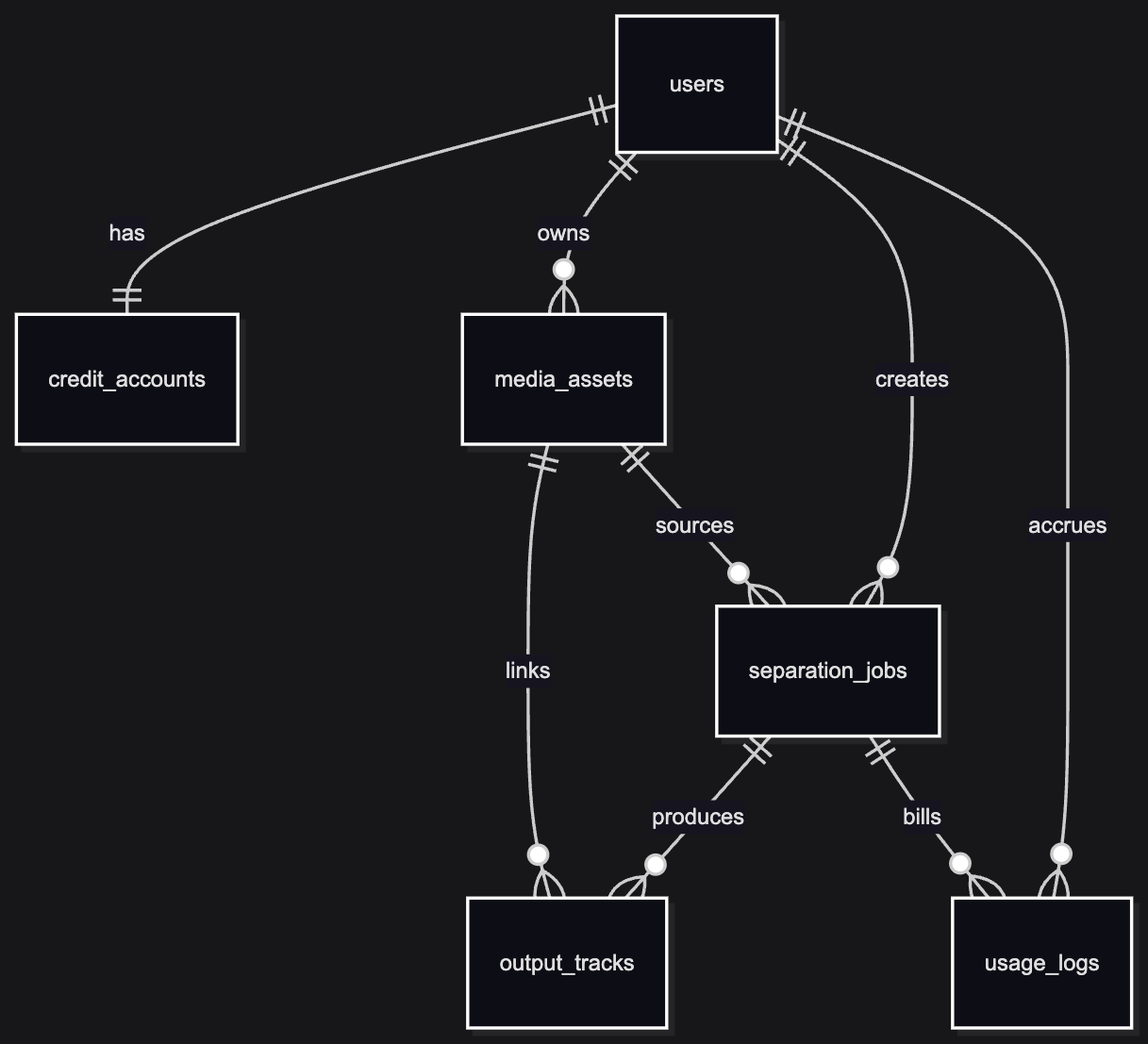
The entities we care about line up with that story:
- User — identity, tier, limits (eventually).
- Media asset — upload metadata plus an object-storage key; the file is not in Postgres.
- Separation job — the async unit of work: status, a JSON snapshot of settings, retries, link to the asset, optional idempotency key so “same file + same intent” does not spawn duplicates by accident.
- Stem / output track — one row per output file (vocals, drums, whatever the model emits) with its own storage pointer.
- Usage / audit — credits burned, GPU time if we track it, a trail for support and cost guardrails.
Visual: how the tables relate (first migration)
This matches what Alembic creates today—blobs stay in S3; these are pointers and lifecycle, not file bytes.
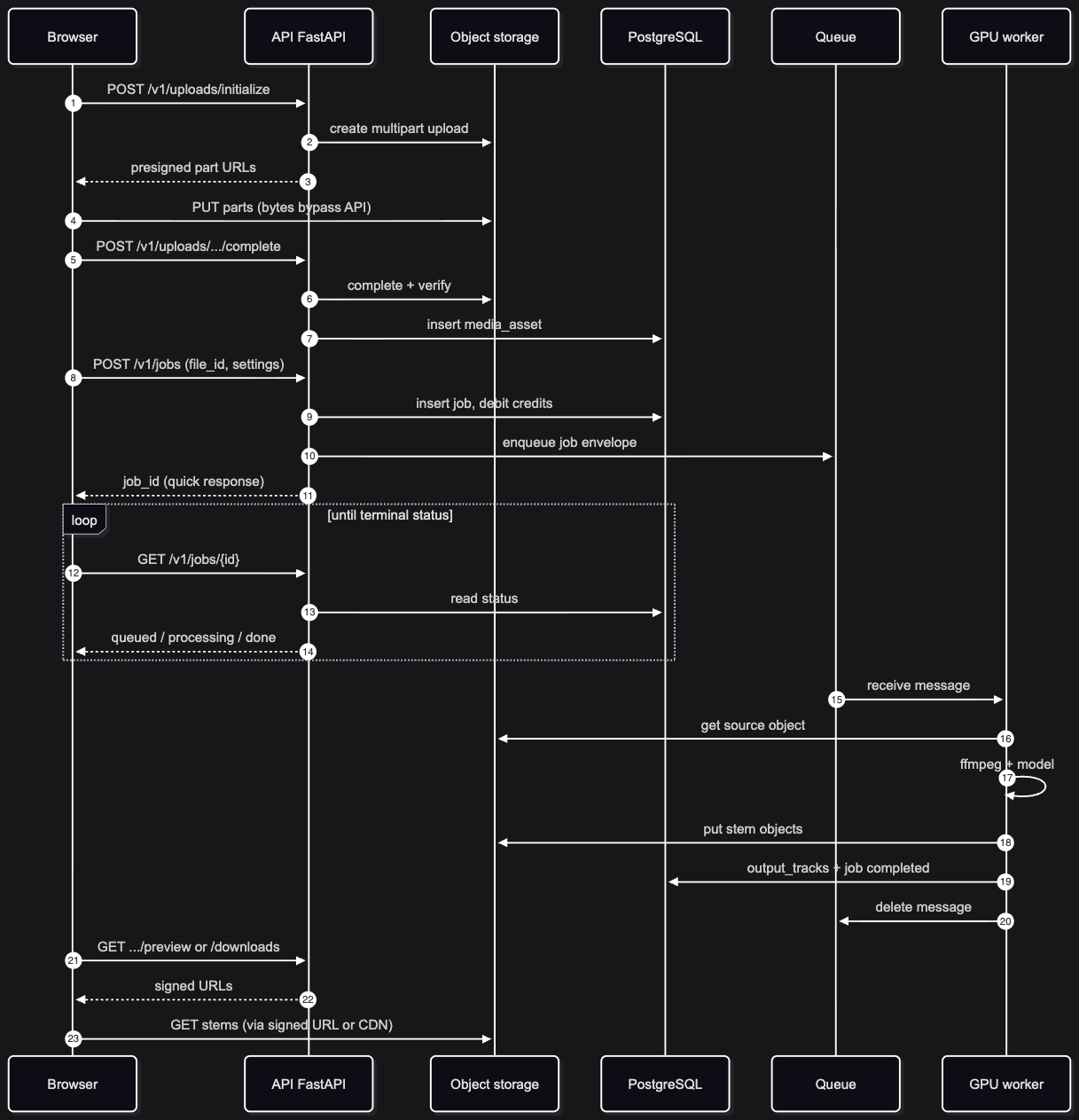
Happy path, sketched: client uploads direct to object storage (presigned multipart, not through the API body), sends one payload on “Separate” with file id and settings, gets 202 (or 201) + job id, workers run the model, client polls (WebSockets later if we need them), downloads via short-lived signed URLs or redirects toward a CDN.
Visual: happy path in time (browser → API → worker)
Non-functional requirements, in human terms
We wrote these up interview-style so we would not hand-wave them later:
| Area | The constraint in plain English |
|---|---|
| Scalability | API and GPU workers are separate; workers scale on queue depth, not on HTTP traffic. |
| Availability | Aim for serious uptime (think 99.9% class); multi-AZ when we are on AWS; don’t require global consensus on “job is processing.” |
| Latency | Interactive API paths stay sub–200 ms where reasonable; minutes of GPU time are fine if the UX is async + honest progress. |
| Reliability | No silent loss of uploads; queue visibility timeouts and retries; idempotent job creation where we can. |
| Cost | Autoscale workers down; lifecycle/TTL on blobs; spot or preemptible only where we can tolerate interruption. |
| Security | Real JWT (or equivalent) plus ownership checks; signed URLs for bytes in and out. |
Metrics we are actually designing for (year one)
We are not sizing the API like a viral read-mostly app. Early months will likely be low user volume; the design still has to be profitable and sane at that baseline. The scary line item is idle GPU time, not REST RPS.
Engineering targets (working set):
| Metric | Target | Why it matters |
|---|---|---|
| Average jobs / day | ~450 | Steady-state load for worker sizing and credit math. |
| Peak capacity planning | ~1,800 jobs / day | Headroom for campaigns, press, or a lucky traffic spike without redesigning the queue story overnight. |
| Concurrent GPU jobs at peak | ~5–10 | This is the real concurrency budget; it maps to GPU fleet size and queue backlog, not to API instance count. |
| Max upload size | 100 MB | Caps ingress, S3 footprint, and worst-case model I/O; aligns with “chunk uploads for reliability, don’t pretend the API is a pipe.” |
| Max media duration | 5 minutes | Keeps GPU occupancy predictable; pairs with credit tiers by length (below). |
| Max concurrent jobs per user | 10 | Abuse and cost guardrail; stops one account from pinning the whole queue. |
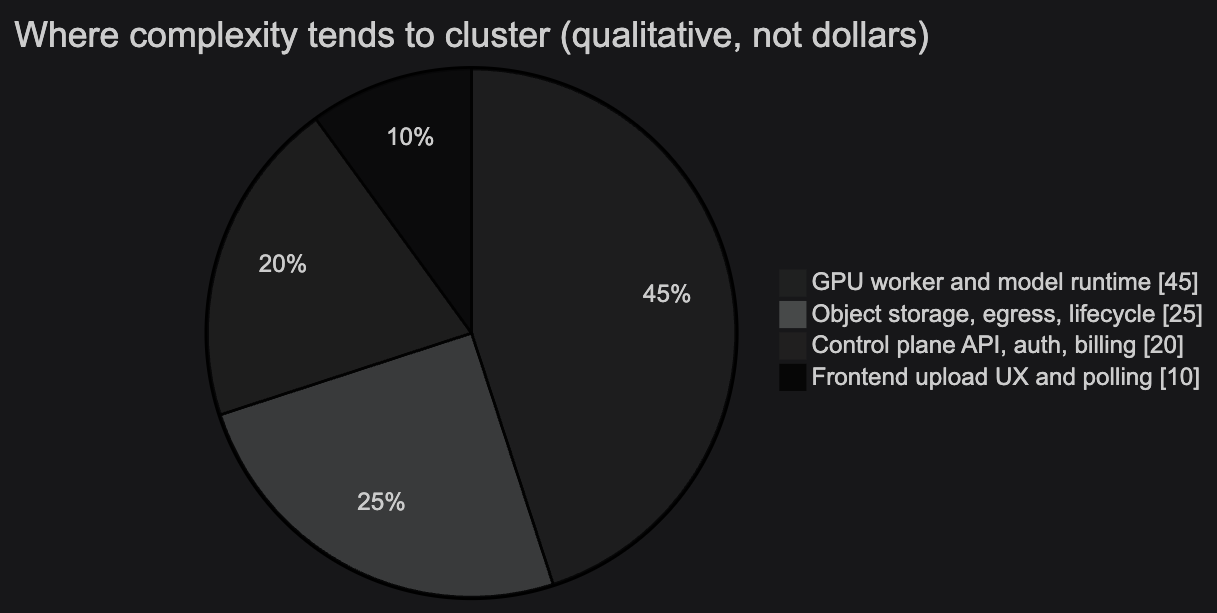
Takeaway: the system is GPU-concurrency bound, not API-throughput bound. When someone asks “will it scale?”, the honest first answer is queue depth, worker count, and dollars per GPU-hour—then egress and storage—not “how many FastAPI workers.”
Credits (MVP intent): burn scales with job size so margin does not collapse on long files. A concrete rule we like: 1 credit up to 30s, 2 credits for 30s–2m, 4 credits for 2–5m. Pack pricing is still an experiment; what is fixed in the design is credits map to duration bucket, not a flat fee per click.
Visual: where the heavy cost usually sits (qualitative)
Not to-scale engineering intuition—useful when someone optimizes the wrong layer.
What we put on paper
The repo’s architecture/ folder is doing real work:
system_design.md— the long-form source of truth: product goals, entities, API contracts, failure modes, billing, edge cases.high_level_system_design.md— the overview with control plane vs media vs compute, Mermaid diagrams for upload path, job path, billing, and labeled edges (who calls whom, with what protocol).implementation_tasks.md— a phased backlog from foundation through worker, downloads, frontend, AWS, admin, and retention—so we don’t implement billing before we can finalize an upload.senior_system_design.mdandsystem_design_interview_format.md— alternate framings and interview-style structure when we want to stress-test the story.
If you are tracing decisions, start with high_level_system_design.md for the picture, system_design.md for depth, and implementation_tasks.md for order of operations.
Visual: control plane vs data plane (whiteboard version)
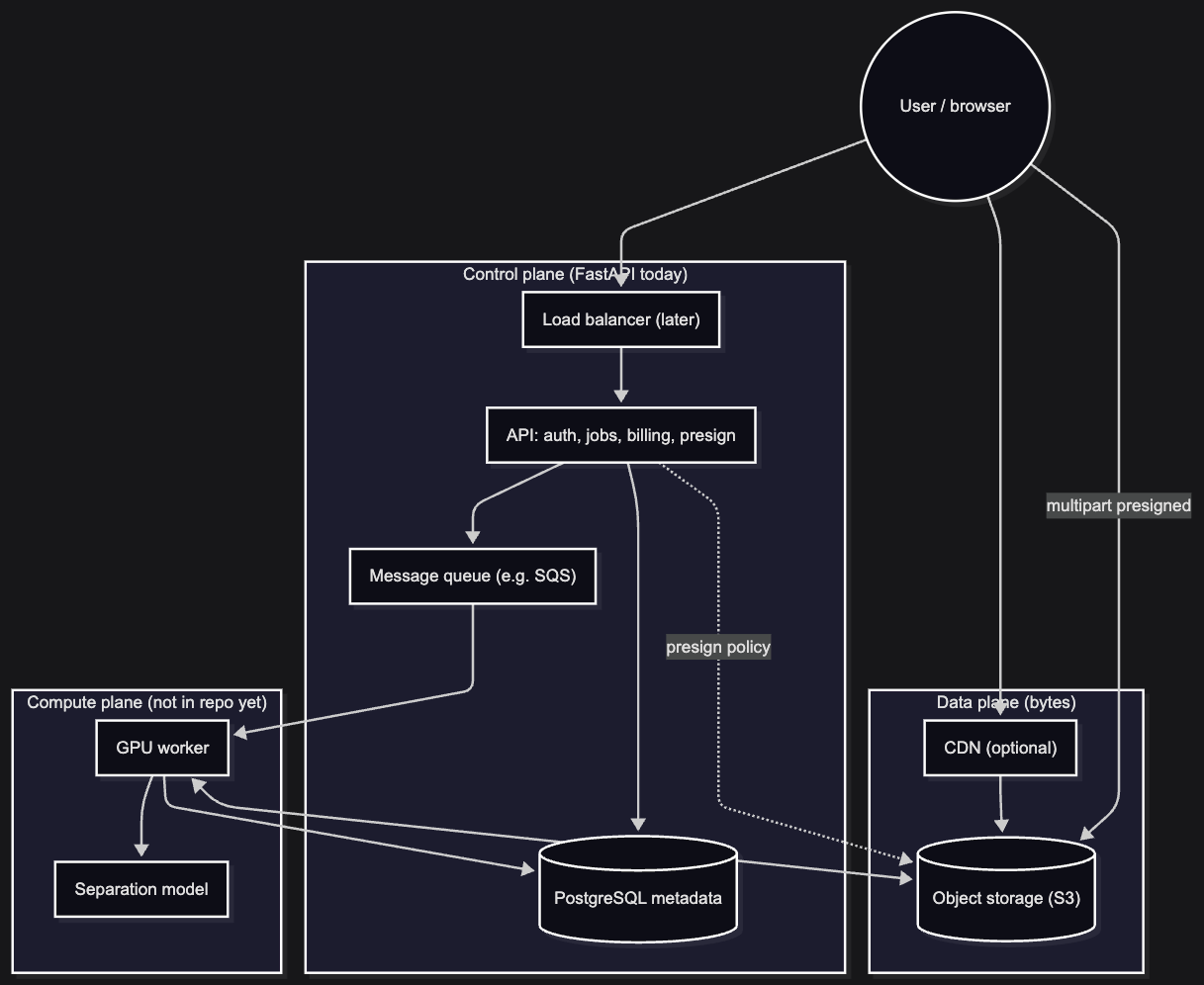
Visual: end-to-end boxes and arrows
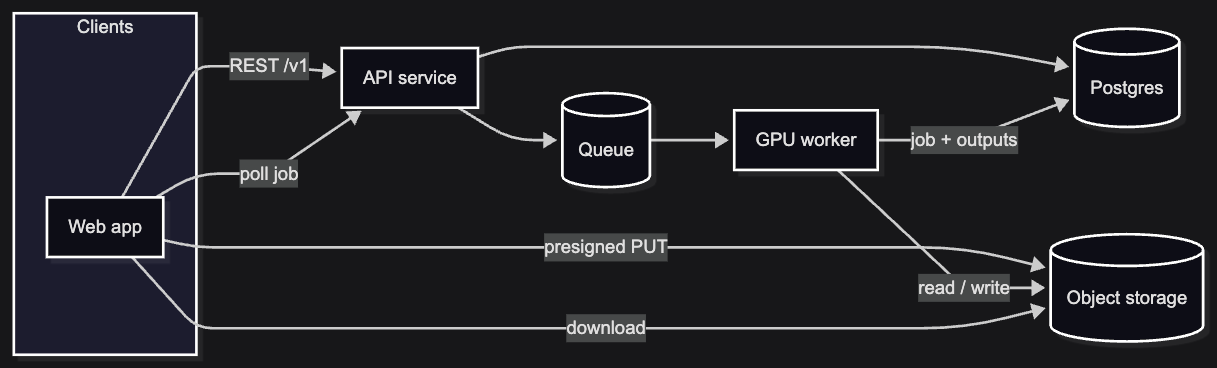
API v1: endpoints and why we shaped them this way
The API is the control plane: auth, metadata, credits, presigns, job lifecycle, and short-lived URLs for bytes. It should never become the bulk data path for 100 MB objects.
Auth
POST /v1/auth/oauth/login— exchange provider flow for a session/JWT; keeps login off custom password soup in v1.GET /v1/me— one place for profile + account context the UI needs on every session.
Uploads (multipart, direct to S3)
POST /v1/uploads/initialize— start multipart upload, return presigned part URLs (or equivalent). Why: large files on bad networks need part-level retry, not “restart from byte zero.” The API stays small and stateless; bandwidth and memory live on S3 and the client.POST /v1/uploads/{upload_id}/complete— verify parts, finalize object, insertMediaAsset. Why: the server remains the source of truth for what counts as “uploaded”; the client cannot invent a row without completing the pipeline.
Jobs (async unit of work)
POST /v1/jobs— body:asset_id, target sound description,configsnapshot. Debit credits (or validate balance), enqueue to SQS, return 201/202 +job_idquickly. Idempotency-Key (per user): same key + same payload → same job; new key → new job even if the file repeats—so mobile retries are safe without blocking intentional “run it again with different settings.”GET /v1/jobs/{job_id}— status for polling in v1 (simple ops, no WebSocket farm yet). Why: job updates are minute-scale, not tick-scale; polling is acceptable until we need richer progress or push savings at scale.POST /v1/jobs/{job_id}/cancel— set cancel requested; worker cooperates at safe checkpoints. Why: users expect out, but we must not corrupt half-written outputs by hard-killing mid-write.
Preview and download (never stream through Postgres)
GET /v1/jobs/{job_id}/preview— returns short-lived signed URLs (or redirects) for inline playback in the app.GET /v1/jobs/{job_id}/downloads— same idea for download links. Why: objects stay private in S3; the API only mints scoped, expiring access. No public sharing model in v1.
Library
GET /v1/me/library— list assets and recent jobs for “my stuff.”DELETE /v1/me/library/{asset_id}— user-initiated removal; pairs with soft delete in DB + hard delete in S3 per retention policy.
Credits and billing (Stripe Checkout, not Billing subscriptions yet)
GET /v1/me/credits— balance the UI shows before starting a job.POST /v1/billing/checkout-session— start a one-time pack purchase. Why: fits irregular usage, avoids subscription SKU complexity and extra Billing surface while pricing is still moving.POST /v1/billing/webhooks/stripe— apply confirmed payments toCreditAccount; server-side only, idempotent handlers.
Admin (internal dashboard backing)
GET /v1/admin/jobs,GET /v1/admin/queue,POST /v1/admin/refunds,GET /v1/admin/metrics— support, backlog, refunds, coarse health. Why: when GPU jobs fail, ops needs DB + queue truth, not only CloudWatch.
Batch uploads stay a product pattern, not a special entity: each file → one MediaAsset, each processing request → one SeparationJob—simpler status, retry, and cancellation than a batch orchestrator.
What we put in code (honest status)
The backend/ app is a FastAPI control-plane skeleton that already matches the architecture’s shape, without pretending the integrations exist yet.
Shipped in a meaningful sense:
- Application shell —
FastAPIapp,/health, v1 router mounted at/v1, settings viapydantic-settings(defaultdatabase_urlis SQLite for local ease; production is intended to be Postgres). - ORM models —
User,CreditAccount,MediaAsset,SeparationJob,OutputTrack,UsageLog, aligned with the design (soft-delete columns where planned,config_jsonon jobs, unique(user_id, idempotency_key)on jobs). - Alembic — an initial migration that creates those tables and indexes so schema changes stay reviewable and repeatable.
- Route map — routers exist for auth, me (profile, library, credits), uploads (initialize / complete), jobs (create, status, cancel, preview, downloads), billing (checkout + Stripe webhook), and admin—so OpenAPI already documents the surface we intend to implement.
Still explicitly stubbed (501 or placeholder): OAuth/JWT, S3 multipart orchestration, SQS enqueue, Stripe, real GET /v1/me from the database, library and credits endpoints, job lifecycle, signed URLs, GPU worker—everything that touches AWS, money, or the model. Auth today is a Bearer token treated as an opaque user id in deps.py: enough to thread dependency injection through handlers until real verification lands.
In debug mode, the app calls SQLModel.metadata.create_all for convenience; production intent is Alembic-only, as the task list says.
So the accurate headline is: we have a schema and an API map that mirror the design; we have not wired the messy integrations yet. That is a deliberate order—wrong schema is expensive to unwind; wrong S3 policy is fixable once the flows are right.
Visual: what exists today vs what is next

How this lines up with the outline you may have seen elsewhere
We also captured a longer internal outline (problem → goals → assumptions → scale → stack → components → entities → API → flows → failure modes → cost). The sections above spell out the headline metrics, endpoint list with rationale, and credit buckets we care about in public; the rest (retention days, worker retry counts, reconciliation jobs) stays in architecture/ until a future post.
We also captured a shorter outline (requirements → NFRs → scale → APIs → entities → one or two architecture diagrams → defer ER detail, chunking, DLQ math, cost models to later parts). This post is the companion that says: that outline is still the narrative spine, and the repo now contains the first concrete artifacts—migration + route stubs—that grow from it.
The API outline we care about is unchanged in spirit: presigned multipart upload, POST /v1/jobs returning a job id quickly, GET /v1/jobs/{id} for polling, preview and download endpoints that hand back signed access, idempotency and per-user concurrency limits when we implement job creation. None of that is fiction; it is reflected in file names and paths under backend/app/api/v1/.
What we are not claiming yet
- No worker process, no SAM (or other model) integration in this repo yet.
- No Stripe live path, no OAuth provider wired.
- No S3 bucket, no SQS queue—only the contracts and tables that assume they will exist.
That list is not embarrassment; it is scope discipline. The architecture work bought us agreement on planes (control vs data vs compute) and entities before we drowned in boto3 and CUDA.
Closing
So far, “architecture” for SplitSound means a coherent story (documents + diagrams), a database shape that matches that story, and an API outline compiled into real modules—even if most handlers still return 501 Not Implemented. The next chapters are boring in a good way: initialize multipart upload, finalize asset, debit credits and enqueue, then a worker that can prove the loop.
If you are building something similar, you do not need our exact stack to steal the move: freeze the metadata model and route list early, implement bytes and GPUs only after those stop moving, and write the phased task list before you hero-coder your way into a migration nightmare.
We will keep building in public; the implementation tasks file is the rough episode guide.